Our Approach Overview
- We pretrain an image backbone encoder on language-annotated images from both simulation and real-world demonstrations of a task.
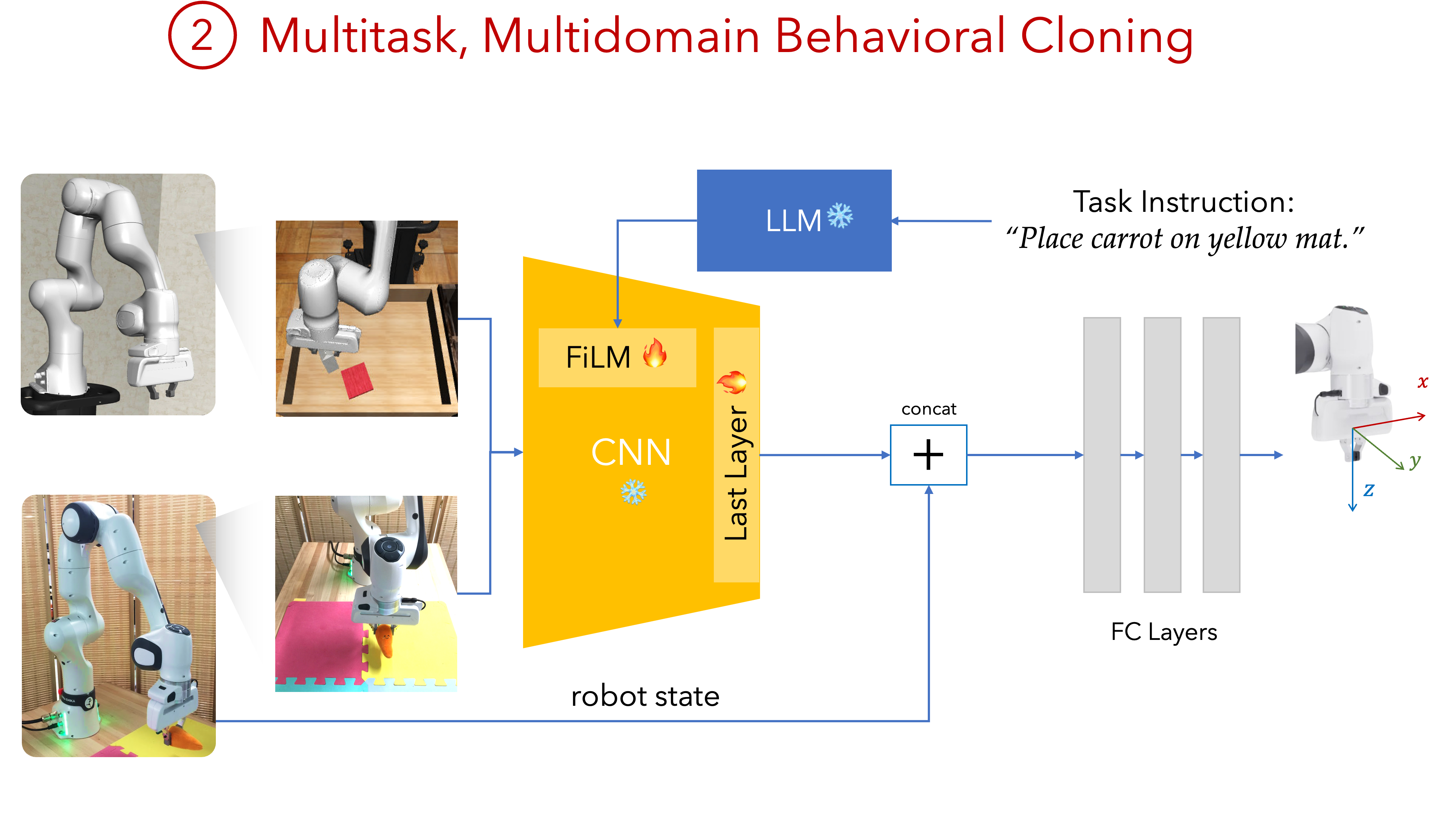
- We then freeze this encoder and use it as the backbone of our policy. We finetune trainable adapter modules and a policy head on action-labeled demonstrations from both sim and real tasks.
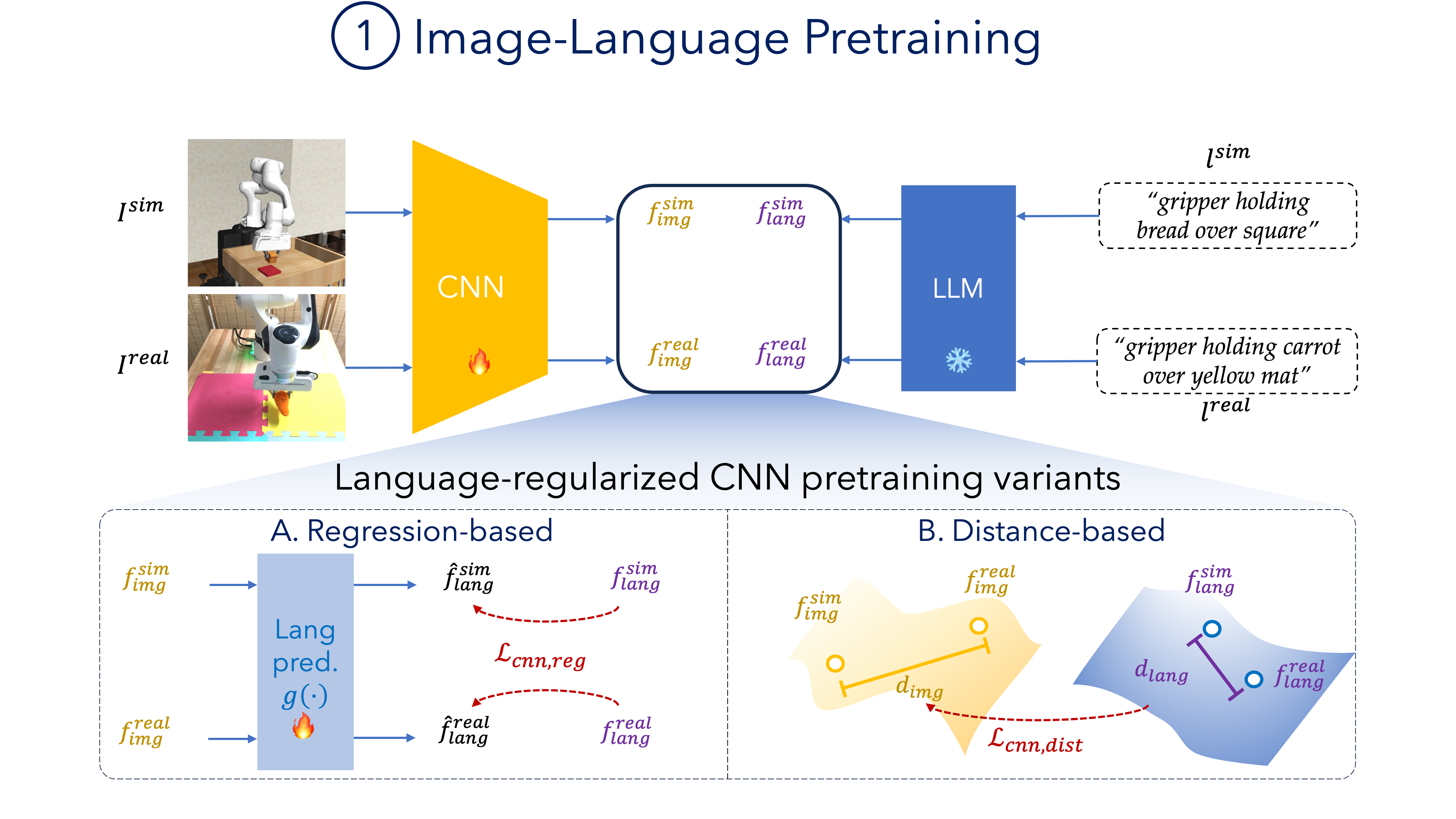
Language Labeling
We annotate trajectories with language labels. Our scripted policy automatically applies labels to the demonstration according to the progress and current stage of the trajectory (see video below). We also show that we can label previously-collected trajectories using off-the-shelf vision-language models.
Experiments
Task Suites
Our Policy Evaluation Rollouts
Baselines
We evaluate against three classes of baselines: no pretraining, vision-language pretrained baselines (R3M and CLIP), and other popular sim2real methods (MMD, Domain Randomization, Automatic Domain Randomization with Random Network Adversary (ADR+RNA)).
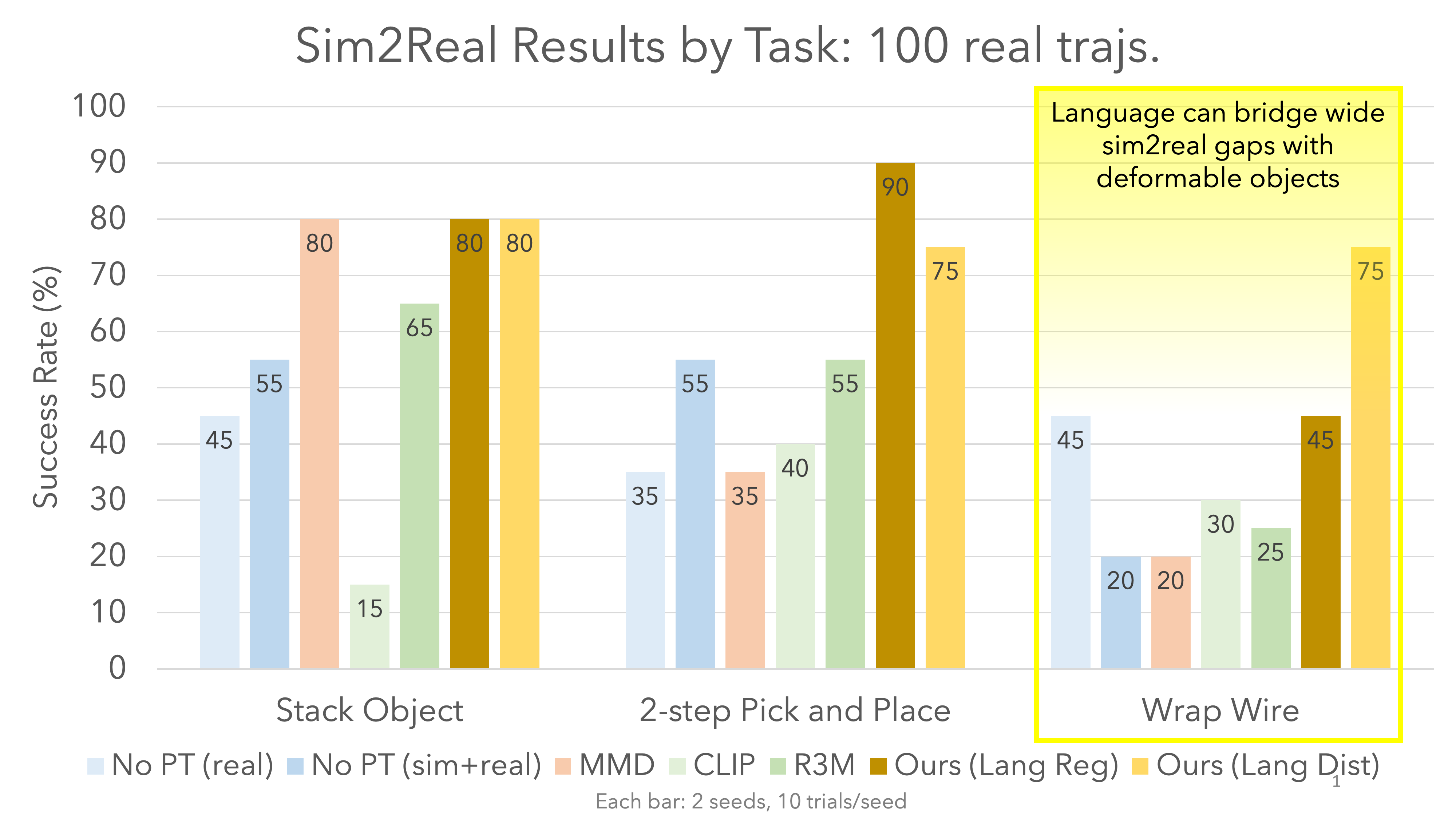
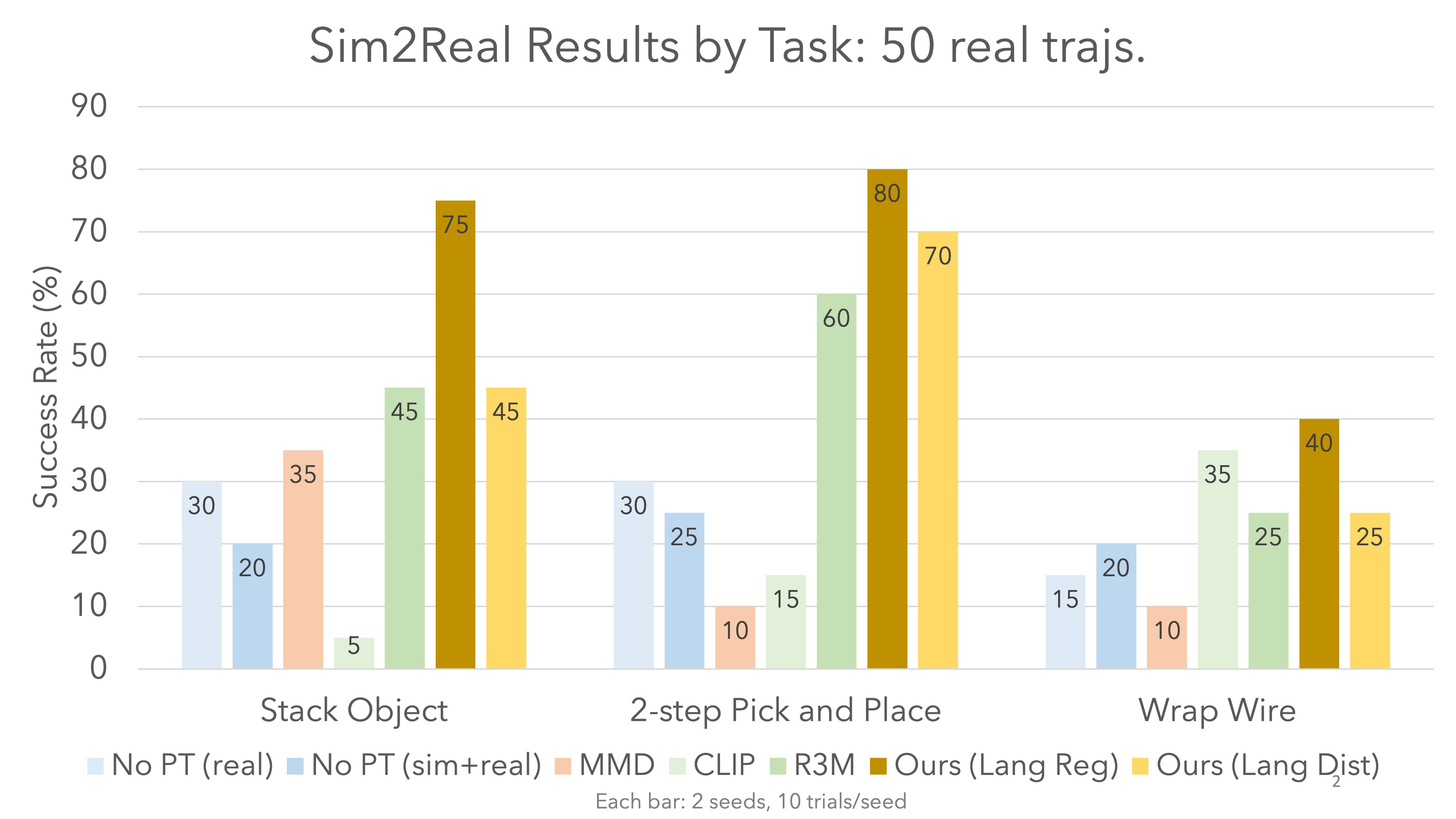
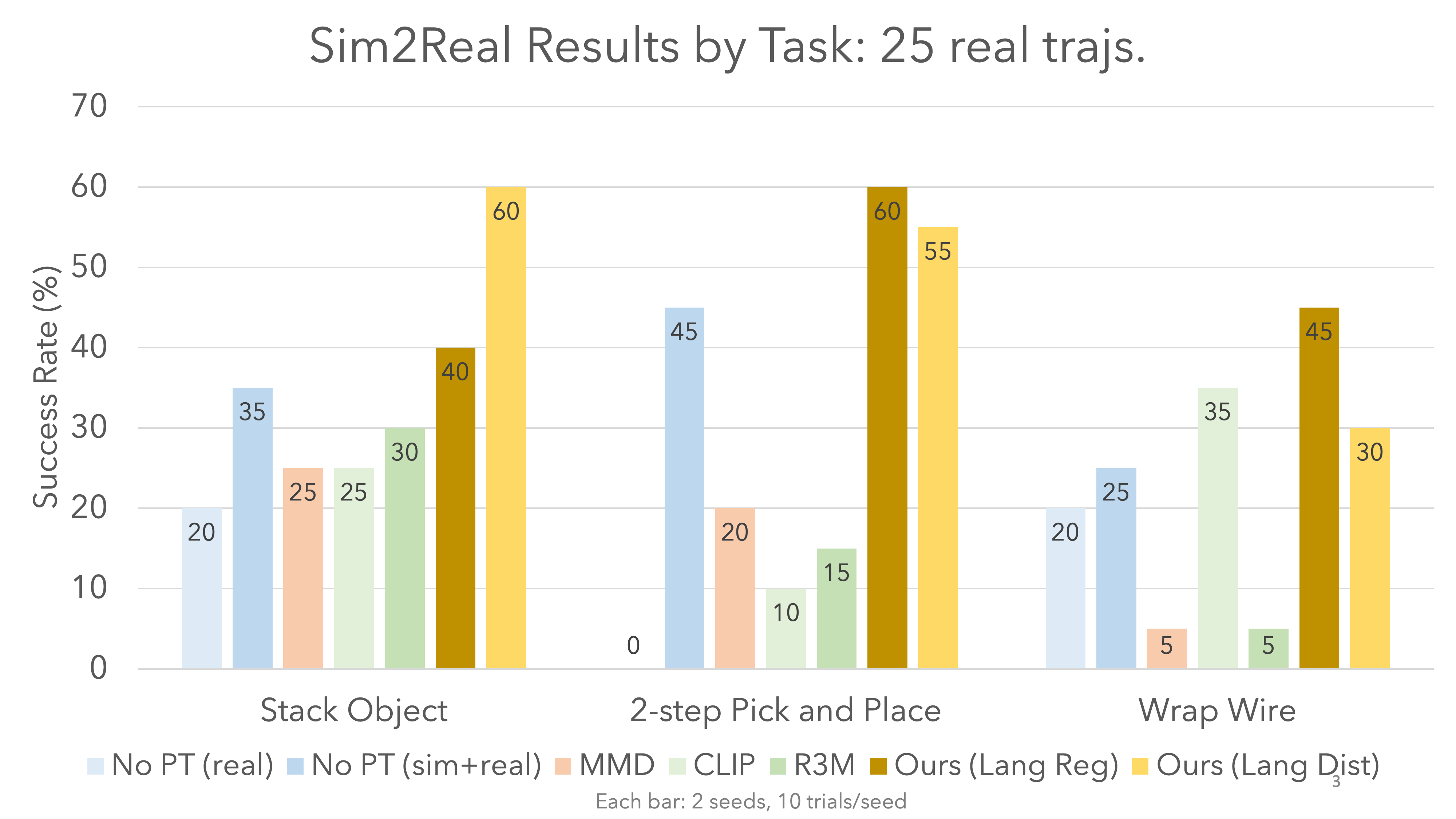
Results
Our method outperforms all baselines. Despite being pretrained only on a few hundred trajectories of image-language pairs, our method outperforms CLIP and R3M, which were trained on internet-scale data.
Ablations
What is the effect of language on pretraining?
To quantify the impact of natural language on our pretraining approach, we use an alternate pretraining objective of classifying the stage of the trajectory rather than regressing to the language annotation associated with that stage of the trajectory. We find that language provides a measurable benefit of roughly 10-20% across our three task suites, especially in multi-step pick-and-place, perhaps because pretraining with language leverages similarities in language descriptions between the first and second steps of the pick-and-place task.
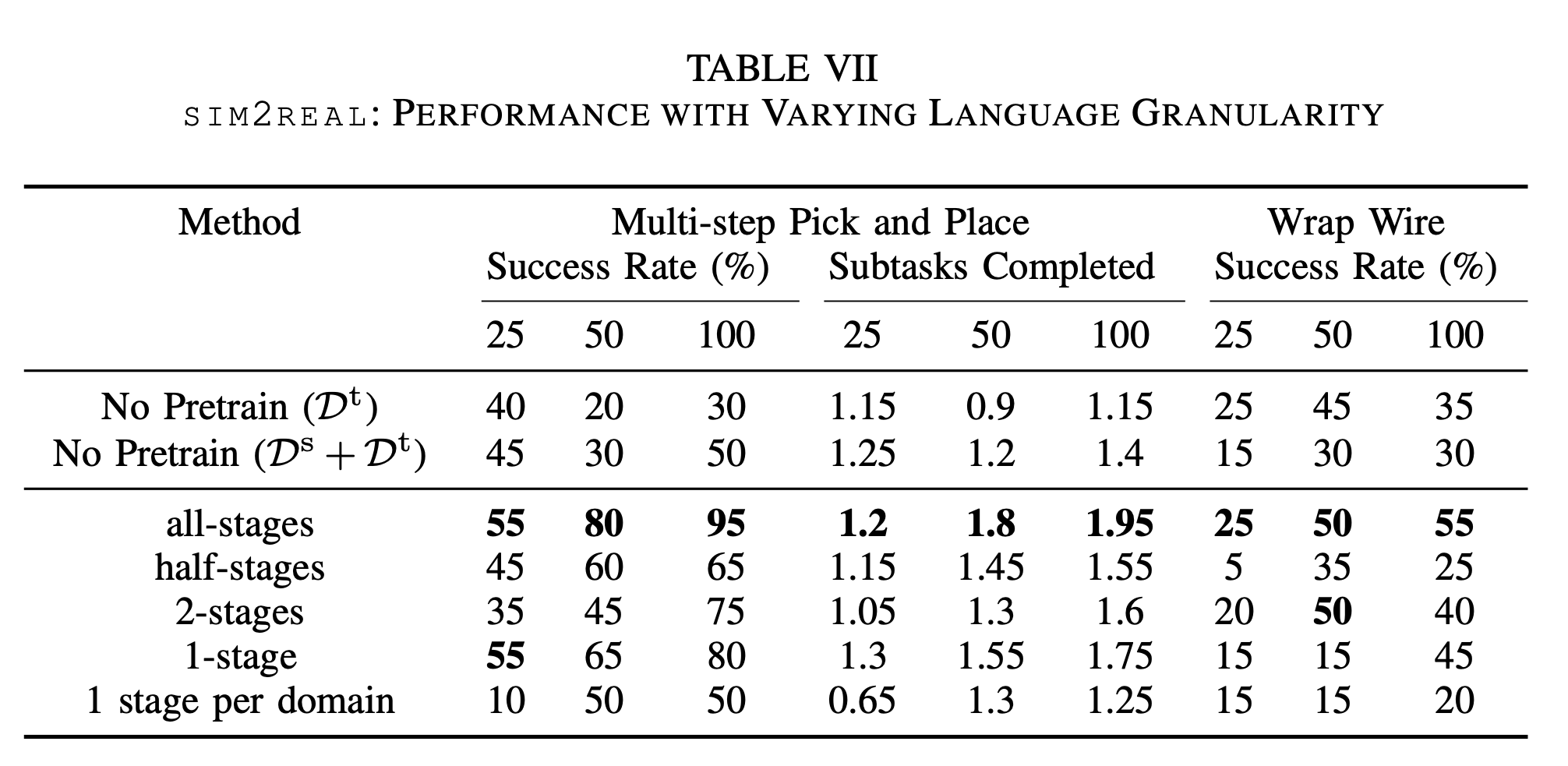
How granular does the language need to be?
To examine the impact of decreasing language granularity on sim2real performance, we experiment with varying numbers of unique annotations on each trajectory. In the extreme case, the entire trajectory has only a single stage, which means that all images across all trajectories of a task have the same language description embedding. In general, decreasing language granularity hurts performance slightly. Still, our method is robust to lower granularity, which matches our hypothesis that our pretraining approach provides significant performance gains simply by pushing sim and real images into a similar embedding distribution even if the language granularity is extremely coarse.
BibTeX
@inproceedings{yu2024lang4sim2real,
title={Natural Language Can Help Bridge the Sim2Real Gap},
author={Yu, Albert and Foote, Adeline and Mooney, Raymond and Martín-Martín, Roberto},
booktitle={Robotics: Science and Systems (RSS), 2024},
year={2024}
}